
「robots.txtって何を書けばいいの?」「間違えると検索に出なくなりそうで怖い…」
このような不安を感じながら設定を後回しにしているWeb担当者は少なくありません。
本記事では、robots.txtの書き方・設定方法・SEO効果・AIクローラーへの対応について解説しました。
最後まで読めば、自分のサイトに合った設定を迷わず実装できるようになり、無駄なクロールをなくして検索評価の向上につなげられます。
robots.txtとは|クローラーへの指示書が果たす役割
robots.txtは、検索エンジンのクローラーがサイトをどのように巡回するかをコントロールするためのテキストファイルです。
適切に設定することで無駄なクロールを減らしてサイト全体の評価を底上げできますが、誤った設定は検索順位の大幅な低下を招くこともあります。
具体的には、以下の2つの観点から解説します。
- クロールバジェットとインデックスの仕組みを理解する
- noindexや.htaccessとの明確な違い
それぞれ順番に見ていきましょう。
クロールバジェットとインデックスの仕組みを理解する
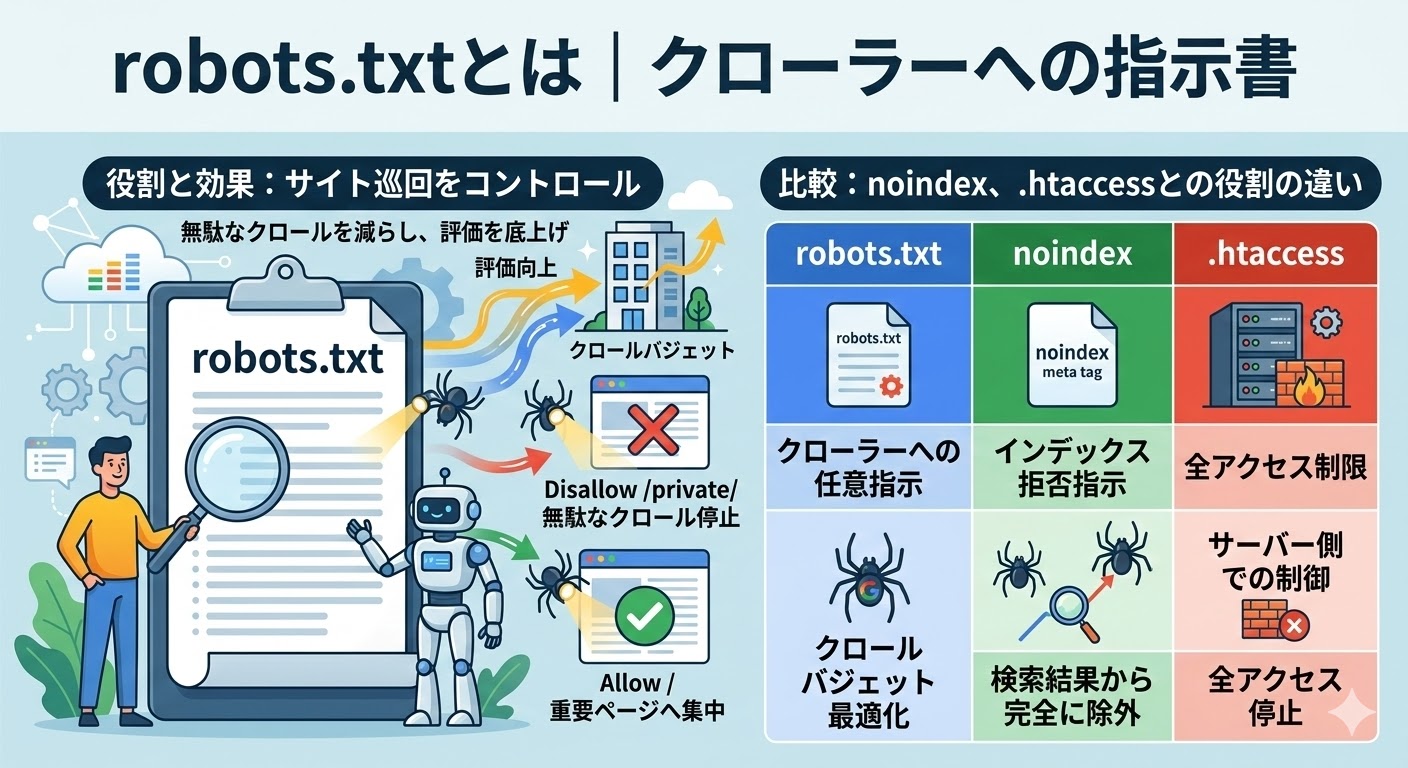
robots.txtとは、検索エンジンのクローラーに対してサイトのどのURLにアクセスしてよいかを伝えるファイルです。
Google検索セントラルによると、このファイルの主な目的はサーバーへのリクエストを過負荷にしないようにすることであり、ページをインデックスから除外するための仕組みではありません。
クロールバジェットとは、Googlebotがサイトに一定期間内に割り当てるクロールのリソース総量を指します。
大規模なサイトでは、この限られたバジェットを重要なページに集中させるためにrobots.txtで不要なページへのアクセスを制限することが有効です。
インデックスはクロールの後に行われるプロセスであり、robots.txtでブロックしたページでも外部リンクが存在する場合にはインデックスされる可能性があります。
参考:robots.txtの概要とガイド|Google検索セントラル ※「robots.txtファイルとは」の項目より、クロール管理目的と非インデックス機能についての記述を引用
関連記事:オウンドメディアのSEO対策5選!内部SEOとAI対策も解説します
noindexや.htaccessとの明確な違い
robots.txtはクローラーの巡回を制御するファイルですが、noindexタグはクロールを許可した上でインデックス登録を拒否する指示です。
この2つはよく混同されますが、robots.txtでブロックしたページは検索結果から消えるとは限らないという点が重要な違いです。
ページを検索結果に表示させたくない場合は、noindexタグをクローラーに読み込ませてから、robots.txtでのブロックを検討する順序が正しいです。
.htaccessはApache系サーバーでアクセス制御を行うファイルで、人間を含むすべてのアクセスを制限できますが、robots.txtはあくまでクローラーへの任意のリクエストにすぎません。
用途に応じて3つのツールを使い分けることが、意図したとおりのクロール・インデックス管理につながります。
関連記事:カノニカル(canonical)タグとは?SEO効果や設定方法を解説
robots.txtが必要なサイトとSEO効果の実態
robots.txtはすべてのサイトが必須で設置すべきファイルではありませんが、サイトの規模や構造によっては設定の有無でSEO効果に大きな差が出ることがあります。
どのようなサイトに設置が効果的で、小規模サイトにはどう判断すべきかを整理します。
以下の2つの観点から解説します。
- 大規模サイトでクロール最適化が効く理由
- 小規模サイトは設置しなくていいのか?
順番に確認していきましょう。
大規模サイトでクロール最適化が効く理由
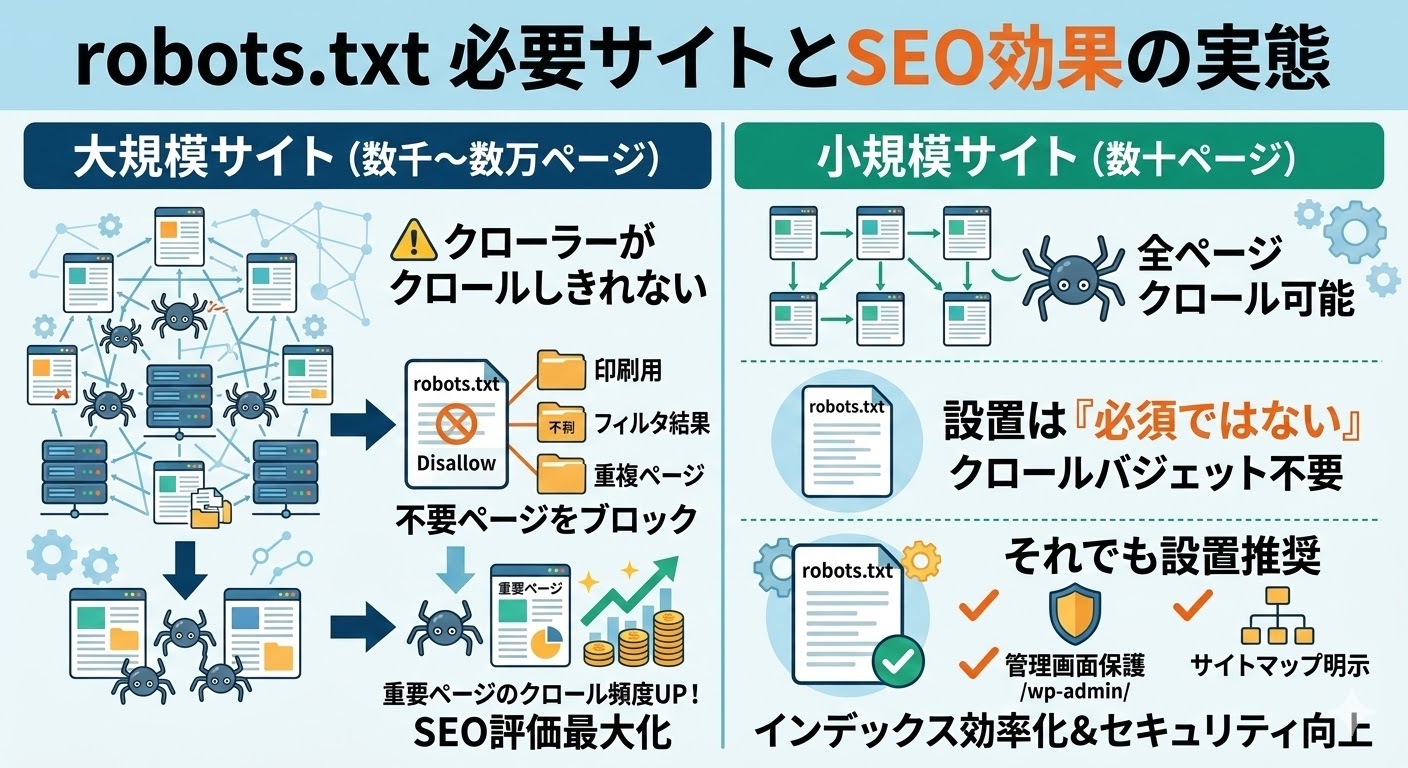
ページ数が数千〜数万規模の大規模サイトでは、Googlebotがすべてのページを定期的にクロールしきれないことがあります。
クロールバジェットが限られているため、商品ページやブログ記事など収益に直結するページに優先的にバジェットを使わせることが、SEO評価の最大化につながります。
robots.txtでフィルタリング結果ページや印刷用ページ、重複した検索結果URLなどを除外することで、重要ページへのクロール頻度が増加する傾向があります。
Googleが公式に言及している大規模サイト向けのクロールバジェット管理ガイドラインでも、不要ページのブロックによるクロール効率化が推奨されています。
ECサイトや大規模ポータルサイトを運用している場合は、robots.txtの適切な設定が検索パフォーマンス改善に直接寄与するでしょう。
参考:robots.txtの概要とガイド|Google検索セントラル ※「robots.txtの使用目的」の項目より、重要でないページのクロールを防ぐ目的についての記述を引用
関連記事:GoogleのSEOガイドライン6選|チェックリスト150個紹介!
小規模サイトは設置しなくていいのか?
数十ページ程度の小規模サイトや個人ブログでは、Googlebotはすべてのページを問題なくクロールできるため、クロールバジェットの最適化は基本的に不要です。
一方でrobots.txtがまったく存在しない場合でも、クローラーはサイト全体をクロール可能な状態として扱うため、機能上の問題はありません。
ただし、WordPressでは管理画面(/wp-admin/)など公開不要のディレクトリが存在するため、最低限のブロック設定は小規模サイトにも有効です。
またrobots.txtはクローラーが最初に確認するファイルであり、サイトマップのURLを記載することでインデックスの効率化にも貢献できます。
規模に関係なく、管理画面の保護とサイトマップの明示を目的に設置しておくことが望ましいでしょう。
関連記事:SEOが難しい理由は?うまくいかない原因と解決策を解説
robots.txtの基本構文と書き方
robots.txtは特定のルールに従って記述する必要があり、構文を誤ると意図しないページがブロックされる危険があります。
本セクションでは、基本ディレクティブの意味から実際にそのままコピーして使えるサンプルまでを解説します。
以下の3つの観点から見ていきます。
- User-agent・Disallow・Allow・Sitemapの意味と使い方
- ワイルドカードとパス指定のルール
- そのままコピーできる記述例サンプル
一つずつ確認していきましょう。
User-agent・Disallow・Allow・Sitemapの意味と使い方
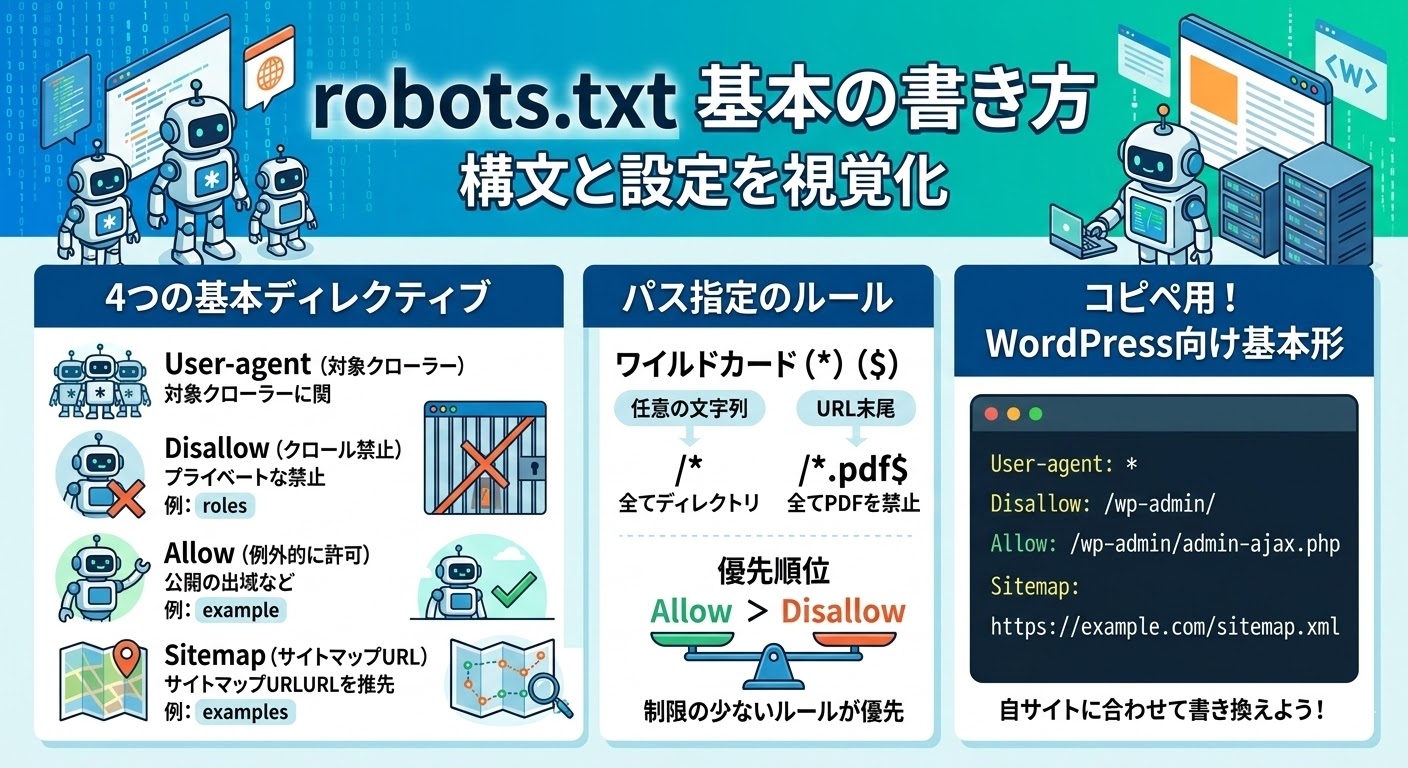
robots.txtを構成する基本ディレクティブは、User-agent・Disallow・Allow・Sitemapの4つです。
「User-agent」はルールを適用するクローラーを指定し、「*」(アスタリスク)はすべてのクローラーを対象とする特別な記号です。
「Disallow」はクロールを禁止するパスを指定し、「Allow」はDisallowで禁止したパスの一部を例外的に許可するために使います。
「Sitemap」ディレクティブにXMLサイトマップのURLを記述することで、クローラーにサイト全体の構造を効率よく伝えられます。
以下の表に各ディレクティブの役割と記述例をまとめました。
| ディレクティブ | 役割 | 記述例 |
| User-agent | 対象クローラーの指定 | User-agent: * |
| Disallow | クロール禁止パスの指定 | Disallow: /private/ |
| Allow | 例外的なクロール許可 | Allow: /public/ |
| Sitemap | サイトマップURLの指定 | Sitemap: https://example.com/sitemap.xml |
Allowは記述しなくてもデフォルトでクロール許可となるため、Disallowで除外した一部を許可する場合のみ利用します。
参考:robots.txtの書き方、設定と送信|Google検索セントラル ※「robots.txtファイルの構成要素」より、各ディレクティブの役割についての記述を引用
関連記事:SEOチェキとは?6つの主要機能と確認できること・使い方を解説!
ワイルドカードとパス指定のルール
robots.txtでは「*」と「$」の2種類のワイルドカードを使ったパス指定が可能です。
「*」は0文字以上の任意の文字列にマッチするため、「Disallow: /*.pdf$」と書けばすべてのPDFファイルへのクロールを禁止できます。
「$」はURLの末尾を示す記号で、完全一致パターンを指定したいときに使います。
ルールが競合する場合、Googleの仕様では「より制限の少ないルール(Allow)が優先」されるため、AllowとDisallowを同じパスに設定する際は意図しない動作にならないか注意が必要です。
パス指定は大文字・小文字を区別するため、ディレクトリ名の表記ミスがないよう設定後に必ず動作確認を行いましょう。
参考:robots.txtの書き方、設定と送信|Google検索セントラル ※「パスを使ったルール」の項目より、ワイルドカードの使い方とルール優先順位についての記述を引用
関連記事:カノニカル(canonical)タグとは?SEO効果や設定方法を解説
そのままコピーできる記述例サンプル
最もシンプルな構成は、全クローラーに全ページのクロールを許可し、サイトマップURLを明示するパターンです。
WordPressサイトの場合は管理画面をブロックしつつ、Sitemapを明示することが一般的な基本形となります。
以下のサンプルは多くのサイトでそのまま利用できる基本テンプレートです。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap.xml
Disallowを空欄にすると、すべてのページへのクロールを許可する意味になります。
コピー後はドメイン部分と対象パスを自サイトに合わせて書き換え、設置後はSearch Consoleで動作を確認しましょう。
関連記事:オウンドメディアのSEO対策5選!内部SEOとAI対策も解説します
サイト別・用途別の設定テンプレート集
サイトの種類や目的によって、最適なrobots.txtの設定は異なります。
WordPressやECサイト、企業サイトなど業態別のテンプレートと管理画面・パラメータURLのブロック例を整理しました。
以下の2つのパターンを解説します。
- WordPress・ECサイト・企業サイト別の書き方
- 管理画面・パラメータURL・重複コンテンツのブロック例
それぞれ確認していきましょう。
WordPress・ECサイト・企業サイト別の書き方
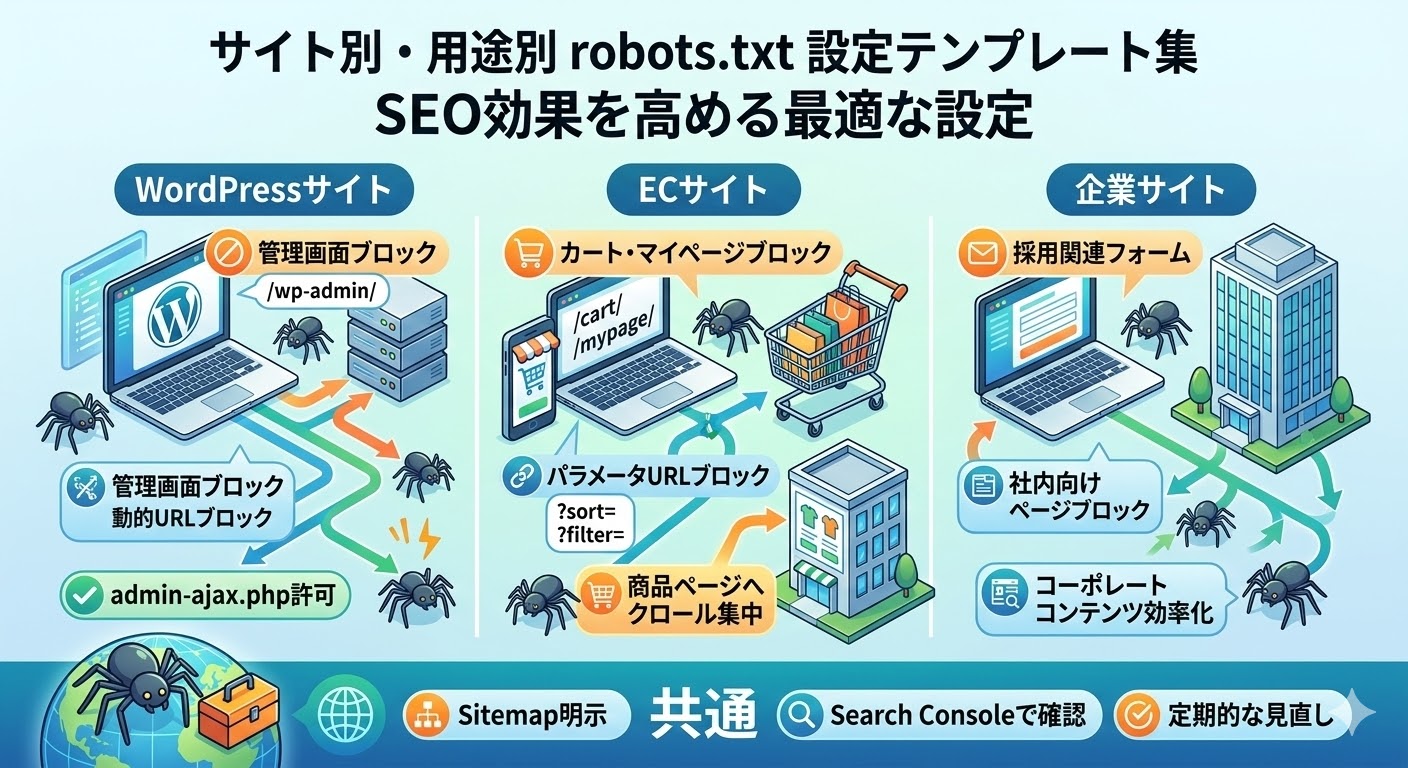
WordPressサイトでは管理画面(/wp-admin/)と一部の動的URLをブロックし、admin-ajax.phpは許可するのが標準的な設定です。
ECサイトではカートページ(/cart/)・マイページ(/mypage/)・フィルタ結果URL(?sort=等のパラメータ含む)をブロックして、商品ページへのクロールを集中させることが効果的です。
企業サイトでは採用関連の候補者向けフォームや社内向けページなどをブロックし、コーポレートコンテンツのクロール効率を最大化することが求められます。
各サイトタイプ共通で、Sitemapディレクティブは必ず記述しておくとクロール効率が向上します。
設定後はURL検査ツールやrobots.txtレポートで意図通りに動作しているかをひとつずつ確認することが重要です。
関連記事:GoogleのSEOガイドライン6選|チェックリスト150個紹介!
管理画面・パラメータURL・重複コンテンツのブロック例
管理画面はほとんどのCMSでデフォルトのパスが公開されており、クロールさせる必要がないため積極的にブロックすることが推奨されます。
URLパラメータによる重複コンテンツはECサイトやポータルサイトで発生しやすく、ソート順・絞り込み条件などを含むURLをDisallowで除外することでクロールバジェットの無駄遣いを防げます。
印刷用ページ(/print/や?print=1など)も重複コンテンツになりやすいため、ブロック対象として検討しましょう。
ただし、すべての重複コンテンツに対する根本的な解決策はカノニカルタグの設定であり、robots.txtはあくまでクロール制御の補助的な手段です。
パラメータURLのブロックは広範になりすぎると重要なページも除外するリスクがあるため、Search Consoleでクロール状況を確認しながら慎重に進めましょう。
関連記事:SEOはオワコン?その理由とAI普及時代の生き残り戦略
AIクローラーをブロックすべきかの判断基準
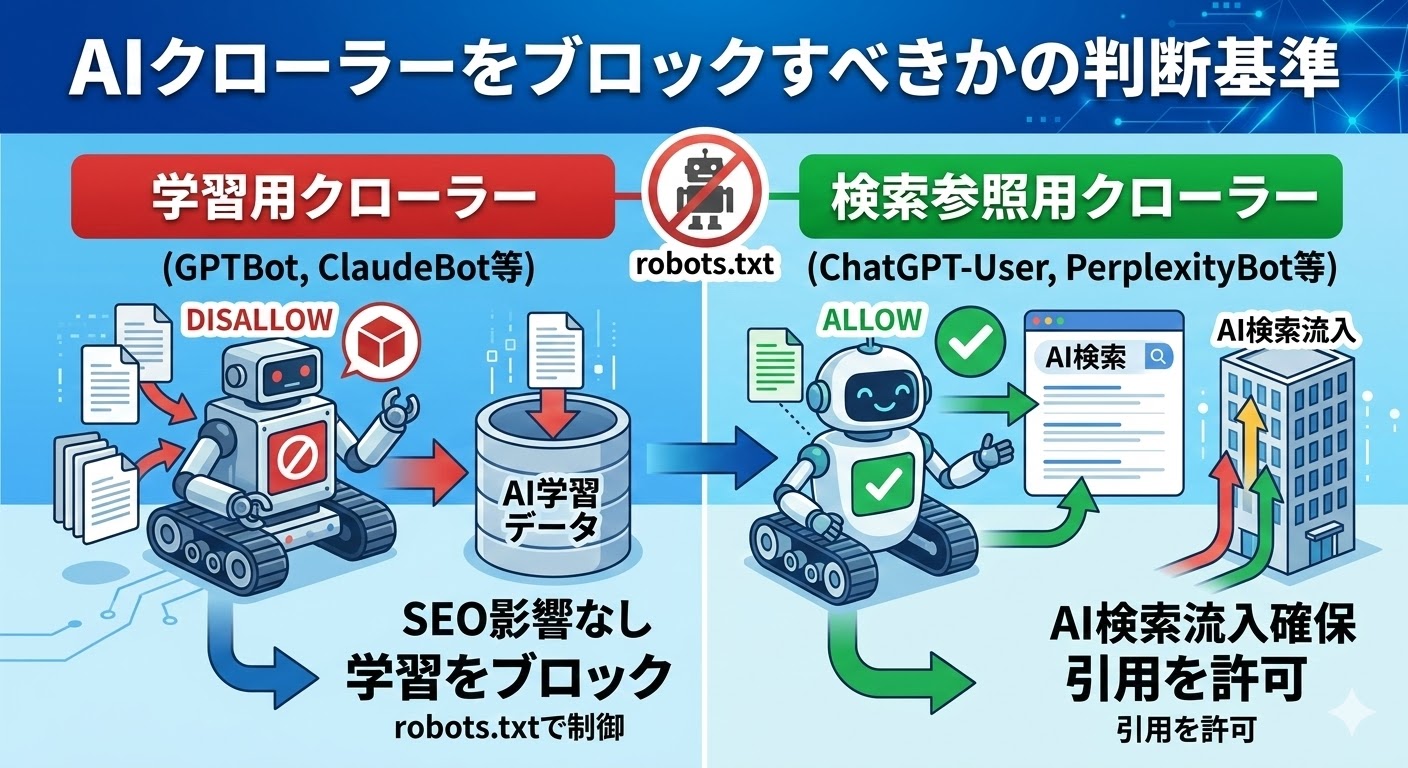
ChatGPTやClaudeなどの生成AIサービスが独自のクローラーを運用しており、robots.txtによる制御が可能です。
ただし、AIクローラーをブロックした場合の影響は通常の検索SEOとは異なるため、目的に応じた判断が必要です。
以下の2点を中心に整理します。
- 主要AIクローラーのUser-agent一覧(GPTBot・Google-Extended等)
- ブロックした場合のSEO・AI検索への影響と考え方
それぞれ詳しく見ていきましょう。
主要AIクローラーのUser-agent一覧(GPTBot・Google-Extended等)
現在、主要なAI事業者がそれぞれ独自のクローラーを運用しており、robots.txtで指定可能なUser-agent文字列が公開されています。
OpenAIのGPTBotはChatGPTのモデル学習に使用されるクローラーで、2023年8月の公開直後から多くのサイトがブロック設定を追加した最初の主要AIクローラーです。
AnthropicのClaudeBotはClaude向けの学習用クローラーで、GoogleのGoogle-ExtendedはGemini等のAI製品向けに通常のGooglebotとは別に用意された制御トークンです。
以下の表に主要AIクローラーの一覧をまとめました。
| AIサービス | User-agent(robots.txt記述) | 用途 |
| OpenAI | GPTBot | ChatGPT学習用クローラー |
| OpenAI | ChatGPT-User | ユーザーリクエストに応じた取得 |
| Anthropic | ClaudeBot | Claude学習用クローラー |
| Google-Extended | Gemini等AI製品向け制御トークン | |
| Apple | Applebot-Extended | Apple AI製品向け |
| Perplexity | PerplexityBot | Perplexity検索用クローラー |
| Meta | Meta-ExternalAgent | Meta AI向け |
| Common Crawl | CCBot | 複数AIが利用するデータセット |
AIクローラーは新規参入が続いており、定期的に一覧を確認・更新することが推奨されます。
関連記事:SEOはオワコン?その理由とAI普及時代の生き残り戦略
ブロックした場合のSEO・AI検索への影響と考え方
GPTBotやClaudeBotをブロックしても、通常のGoogle検索やBing検索のランキングへの影響はありません。
これらのAI学習クローラーと、GooglebotやBingbotといった検索インデックス用クローラーは完全に別の存在として動作しているためです。
一方で、ChatGPT検索やPerplexityなどのAI検索から参照されるためには、それぞれの検索専用クローラー(OAI-SearchBot、ChatGPT-User等)によるアクセスを許可する必要があります。
AI検索経由のリファラートラフィックは急速に増加しており、すべてのAIクローラーを一律にブロックするとAI検索からのサイト流入の機会を失うリスクがあります。
自社コンテンツをAI学習に使われたくない場合は学習用クローラーのみを選択的にブロックし、検索参照用クローラーは許可するという判断が現実的な対応といえます。
関連記事:SEOが難しい理由は?うまくいかない原因と解決策を解説
robots.txtの設置方法・確認方法と設定ミスを防ぐチェックポイント

robots.txtはファイルの設置場所や確認の手順を正しく理解しておかないと、設定した内容が意図通りに機能しないことがあります。
ここでは設置手順・Search Consoleでの確認方法・よくある記述ミスの3点を具体的に解説します。
以下の3つの観点から確認していきます。
- ルートディレクトリへの設置手順
- Search Consoleでの動作確認方法
- やってはいけない記述ミス3選
一つひとつ確認していきましょう。
ルートディレクトリへの設置手順
robots.txtはサイトのルートディレクトリに設置する必要があり、例えばwww.example.comのサイトであれば「www.example.com/robots.txt」がアクセスURLになります。
サブディレクトリ(例:/blog/robots.txt)に設置しても検索エンジンはそのファイルを認識しないため、必ずルート直下への配置が必須です。
テキストエディタ(メモ帳・VSCode等)でrobots.txtを作成し、UTF-8エンコードで保存したうえでFTPソフトやサーバー管理画面からルートディレクトリにアップロードします。
ファイル名はすべて小文字の「robots.txt」とし、「Robots.txt」や「robot.txt」は認識されないため注意しましょう。
WordPressの場合はYoast SEOなどのSEOプラグインを使えばファイルを手動作成せずにダッシュボードから編集できます。
関連記事:SEOチェキとは?6つの主要機能と確認できること・使い方を解説!
Search Consoleでの動作確認方法
robots.txtを設置またはアップロードした後は、Google Search Consoleで正しくGoogleに認識されているか確認することが必須のステップです。
確認方法はSearch Consoleにログインし、左メニューの「設定」→「クロール」セクションの「robots.txt」から「レポートを開く」をクリックします。
レポート画面でステータスが「取得済み」になっていれば、Googleがrobots.txtを正常に読み込んでいることを示しています。
ファイルを更新した直後でレポートに反映されていない場合は、「再クロールをリクエスト」からGoogleに最新ファイルの再読み込みを促すことができます。
URL検査ツールで特定のURLを検査し「robots.txtによりブロックされました」と表示されれば、Disallow設定が意図通りに機能しています。
参考:robots.txtの書き方、設定と送信|Google検索セントラル ※「robots.txtの設定と送信」の項目より、Search Consoleでの確認手順についての記述を引用
関連記事:SEOのおすすめChrome拡張機能20選!初心者からプロも愛用
やってはいけない記述ミス3選
robots.txtの設定ミスは検索トラフィックを大幅に失う原因になるため、以下の3つの典型的なミスは必ず避ける必要があります。
1つ目は「Disallow: /」と記述してサイト全体をブロックしてしまうミスで、特にテスト環境からの移行時に設定が引き継がれるケースが多いです。
2つ目はUser-agentとDisallowの間に空行を入れずに記述するフォーマットエラーで、正しい構文では「User-agent」の後に改行し「Disallow」を続ける必要があります。
3つ目はrobots.txtをインデックスを消すツールと誤解して、すでにインデックスされたページをrobots.txtでブロックするケースです。インデックス削除にはnoindexタグの使用が正しい方法です。
設定後は必ずSearch ConsoleのURL検査ツールとrobots.txtレポートの両方で動作確認を行うことが、ミスを防ぐための最も確実な方法です。
関連記事:カノニカル(canonical)タグとは?SEO効果や設定方法を解説
robots.txtに関するよくある質問
robots.txtに関するよくある質問について解説します。
ブロックするとインデックスからも消える?
robots.txtでクロールをブロックしても、インデックスから自動的に削除されるわけではありません。
外部リンクが存在するページはブロックしてもインデックスされたままになることがあります。
インデックスから除外したい場合は、noindexタグをクローラーに認識させた上でrobots.txtブロックを追加する手順が正しい対処法です。
小規模サイトにrobots.txtは不要?
ページ数が少ないサイトではクロールバジェットの管理は基本的に不要ですが、robots.txtを設置することは推奨されます。
管理画面のブロックとサイトマップURLの明示だけでも、クロールの効率化とセキュリティ面でのメリットがあります。
「不要」ではなく「必須ではないが設置した方が望ましい」という理解が正確です。
WordPressのrobots.txtはどこで編集できる?
WordPressではYoast SEOやAll in One SEOなどのSEOプラグインを使えば管理画面から直接robots.txtを編集できます。
FTPソフトでルートディレクトリに直接アップロードする方法でも対応可能ですが、プラグイン経由の方が操作ミスが少ないためおすすめです。
プラグインが生成した内容とFTPでアップロードしたファイルが競合しないようにすることも注意点の一つです。
robots.txtはすべてのクローラーに効く?
Googlebotなどの信頼性の高いクローラーはrobots.txtの指示に従いますが、すべてのクローラーが必ずしも遵守するわけではありません。
悪意のあるボットや一部のクローラーはrobots.txtを無視する場合があります。
完全なブロックが必要な場合はサーバー側でのIPブロックやベーシック認証などを併用することが推奨されます。
AIクローラーをブロックするとGoogleの検索順位に影響はある?
GPTBotやClaudeBotなどのAI学習クローラーをブロックしても、Googlebotによる通常の検索インデックスへの影響は一切ありません。
Google-ExtendedはGemini等のGoogle AI製品に利用されるトークンであり、ブロックしてもGoogle検索ランキングには影響しないとGoogleが公式に明示しています。
影響があるのはAI検索での引用可否であり、AI検索への露出を望む場合は検索参照用クローラーはブロックしないことが重要です。
まとめ|今すぐrobots.txtを見直そう
本記事では、robots.txtの基本構文から設置手順・SEO効果・AIクローラー対応まで解説しました。
robots.txtは「クロールを管理するファイル」であり、インデックスを直接制御するものではないという本質的な理解が、正しい設定への第一歩です。
設定のたった1行のミスがサイト全体のSEOに影響する可能性があるため、変更後は必ずSearch Consoleのrobots.txtレポートとURL検査ツールで確認することを習慣にしましょう。
AIクローラーについては、学習用と検索参照用を区別して選択的に対応することが、今後のSEO・AI検索両立の鍵です。
まずは自サイトのrobots.txtにアクセスして現状を確認し、不要なページのブロックやサイトマップの明示ができているか見直すところから始めましょう。